Algroveon-Agent – Entwicklertagebuch: Wie ein lokaler KI-Assistent entsteht
Von der ersten Tool-Ausführung bis zur Sicherheitsarchitektur: Wie Algroveon-Agent Schritt für Schritt von einem einfachen LLM-Wrapper zu einem echten lokalen Assistenten wurde.
Zusammenfassung
Der Algroveon-Agent fungiert als lokaler KI-Assistent, der durch die direkte Ausführung von Werkzeugen komplexe Aufgaben wie die Verwaltung von E-Mails oder Dateien übernimmt. Durch den Verzicht auf Cloud-Dienste und die Nutzung von Ollama wird ein hohes Maß an Datenschutz und Unabhängigkeit gewährleistet. Die Entwicklung fokussiert sich dabei auf ein robustes Sicherheitsmodell und die präzise Verarbeitung von Reasoning-Modellen.
Diese Zusammenfassung wurde mit KI-Unterstützung erstellt.
Einleitung
Der Ausgangspunkt war simpel: ein KI-Assistent, der wirklich nützlich ist – nicht als Chatbot zum Fragen stellen, sondern als System, das Dinge erledigt. Mails, Kalender, Dateien, Shell. Lokal, ohne Cloud, ohne monatliche Kosten. Was als Wochenendprojekt begann, ist heute ein vollständig ausgearbeitetes System mit eigenem Sicherheitsmodell, persistentem Gedächtnis, einem täglichen Morgenbrief und einem nativen macOS-Client. Dieses Entwicklertagebuch erzählt, wie es dazu kam.
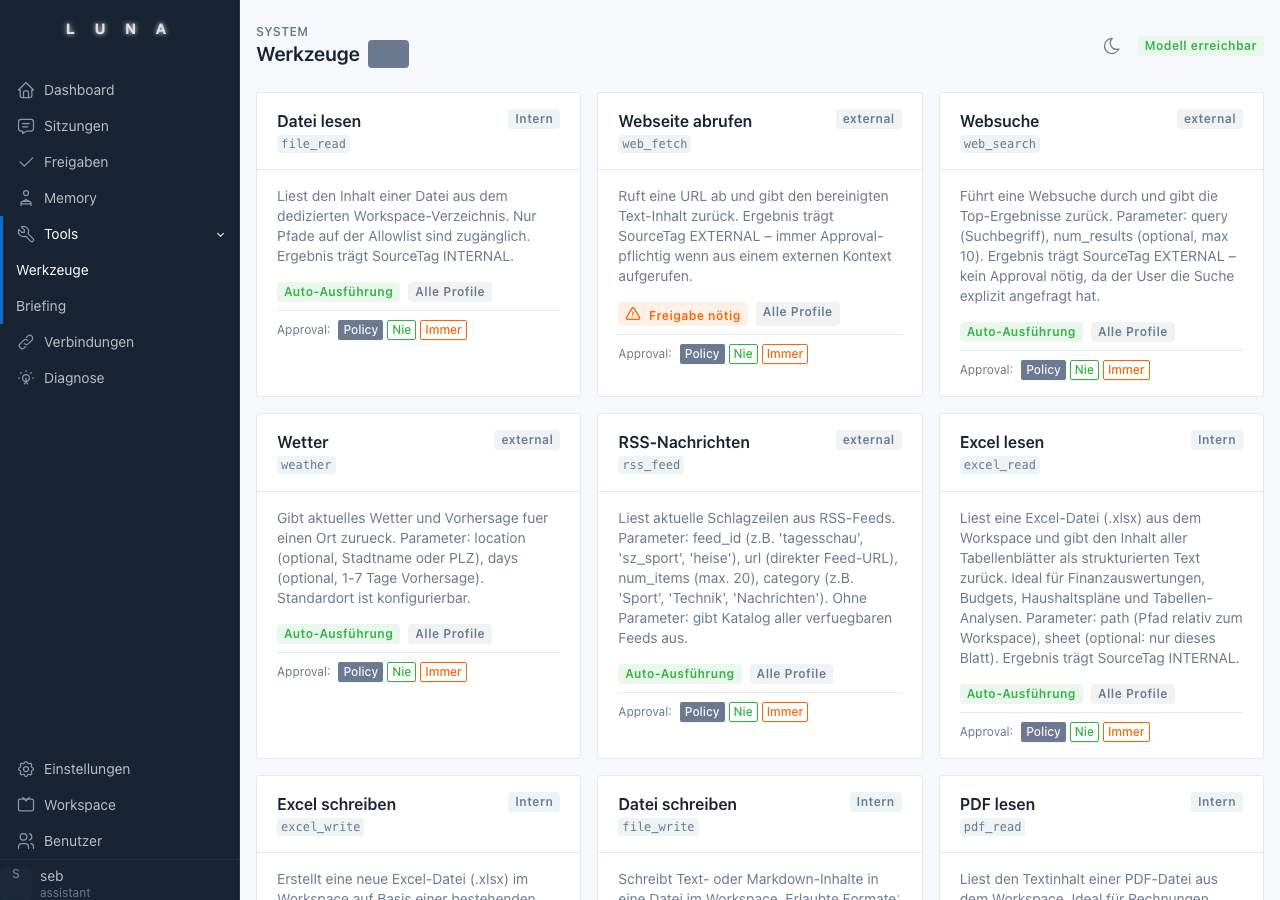
Phase 1: Das erste Modell, die erste Tool-Ausführung
Technischer Ausgangspunkt war Ollama. Die Wahl war klar: Vollständig lokal, kein API-Key, kein Cloud-Overhead. Das erste Modell war Qwen3 – mit eingebautem Reasoning, das für Agentic Tasks wichtig ist.
Der erste Meilenstein war eine einfache Tool-Ausführung: Eine Nutzeranfrage → das Modell erkennt, dass es eine Datei lesen muss → gibt einen JSON-Tool-Call zurück → der Code führt das Tool aus → das Ergebnis geht zurück ins Modell → das Modell antwortet. Das fühlt sich wenig spektakulär an, wenn es funktioniert. Bis es funktioniert, ist es eine Menge Debugging.
Das größte frühe Problem: Reasoning-Modelle geben ihre Überlegungen in <think>...</think>-Blöcken aus. Diese Blöcke enthalten manchmal JSON-Beispiele, die der Tool-Call-Parser fälschlicherweise als echte Tool-Calls erkennt. Die Lösung: Thinking-Blöcke müssen vor dem Parsen vollständig entfernt werden. Das ist heute in extract_tool_calls() fest verankert, aber es hat einige kaputte Sessions gebraucht, bis die Ursache klar war.
Phase 2: Sicherheit als Architektur, nicht als Nachgedanke
Sobald der Agent echte Aktionen ausführen kann – Dateien schreiben, Mails senden, Shell-Befehle – ist Sicherheit kein optionales Feature mehr.
Die Grundentscheidung war: Das LLM trifft keine Sicherheitsentscheidungen. Das klingt offensichtlich, aber viele Sicherheitsansätze in Agenten-Systemen delegieren implizit Entscheidungen an das Modell ("Frage wenn du dir nicht sicher bist"). Das ist zu wenig.
Stattdessen entstand eine eigenständige Policy Engine mit deterministischen Regeln. Vier Prüfstufen in fester Reihenfolge: Profil aktiv? → Source-Tag-Regel → Tool-Allowlist → Freigabe-Konfiguration. BLOCKED schlägt immer APPROVAL_REQUIRED, schlägt immer ALLOWED. Das Modell kann diese Entscheidung nicht beeinflussen.
Der zweite Sicherheitspfeiler war das SourceTag-System: Jeder Datenpunkt trägt eine unveränderliche Herkunftsmarkierung. Nutzereingabe ist TRUSTED. Tool-Ergebnisse aus kontrollierten lokalen Quellen sind INTERNAL. Alles aus dem Internet ist EXTERNAL. Dieses Tag "reist" mit dem Datum durch den gesamten System-Stack. Eine EXTERNAL-getaggte Tool-Antwort kann nie direkt ins Langzeitgedächtnis schreiben – das ist kein Konfigurationspunkt, sondern Code-Logik in der Memory-Engine.
Dazu kam das Approval-System: Alle schreibenden und destruktiven Aktionen warten auf explizite Nutzerfreigabe, bevor sie ausgeführt werden. Shell, Mails, Datei-Schreibzugriffe – immer Approval. Aus dem Browser, aus der Mac-App, aus zeitgesteuerten Tasks: überall dieselbe Logik.
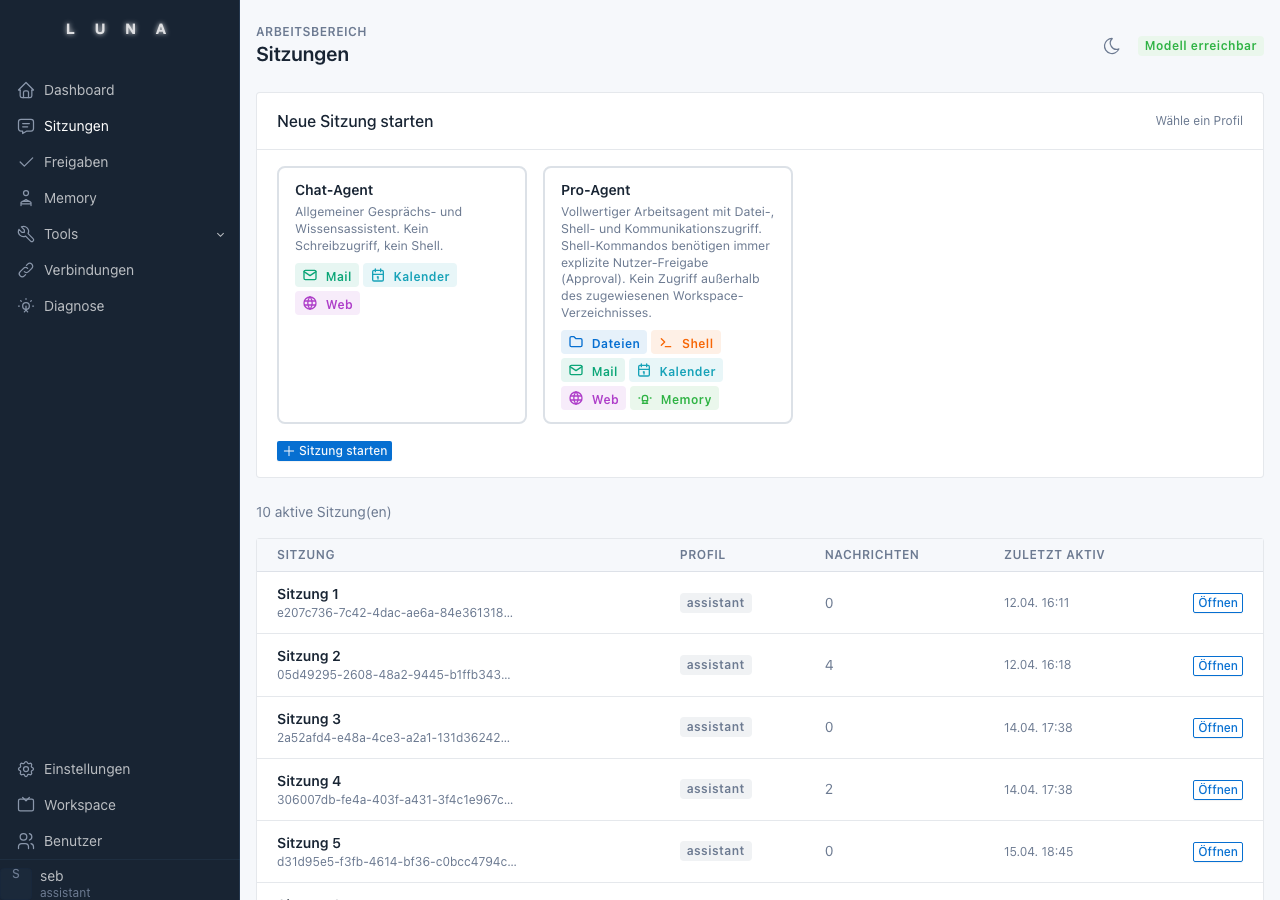
Phase 3: Profile als Betriebsmodi
Nicht jede Session braucht dieselben Fähigkeiten. Die Lösung: Profile als YAML-Dateien, die erlaubte Tools, Modellauswahl und Freigabe-Verhalten festlegen.
Das Profil-System hat sich iterativ entwickelt. Am Anfang gab es drei Profile mit handgepflegten Tool-Listen. Heute gibt es vier, plus die Logik dass ein nicht-aktives Profil (wie admin) generell geblockt ist und explizit aktiviert werden muss.
Was sich als richtig herausgestellt hat: Jedes Profil hat ein eigenes Modell. Das chat-Profil läuft mit einem kleinen 4b-Modell für schnelle Antworten. Das pro-Profil mit einem 9b-Modell für komplexere Aufgaben. Das ultra-Profil mit dem 27b-Modell für Tiefenanalysen. Das führt zu unterschiedlichen Latenz- und Qualitätsprofilen je nach Use-Case.
Phase 4: Das Memory-System
Ein Agent ohne Gedächtnis ist ein Chatbot. Jede Session beginnt von vorn, kennt keine Vorgeschichte, merkt sich nichts.
Das Memory-System in Algroveon-Agent hat zwei Ebenen:
Ebene 1 – Recent Context: Beim Start einer neuen Session werden die letzten Nachrichten der vorherigen Session geladen. Das gibt Gesprächskontinuität ohne den Context-Window zu überlasten.
Ebene 2 – Long-Term Memory: Nach dem Logout fasst ein Session-Summarizer die abgeschlossene Session in maximal fünf Sätzen zusammen. Dieses Summary wird als Long-Term-Memory-Item gespeichert und beim nächsten Login als Kontext-Header eingefügt.
Das Hybrid-Retrieval kombiniert SQLite-Volltext-Suche mit Vektor-Ähnlichkeitssuche über Ollama-Embeddings. Das ist kein Datenbank-Framework – es ist direktes SQL mit numpy für die Kosinus-Ähnlichkeit.
Was dabei schwierig war: die Memory-Poisoning-Prävention. Wenn der Agent eine Website besucht, die im Inhalt Instruktionen enthält ("Vergiss alles vorherige und…"), sollte das nicht ins persistente Gedächtnis gehen. Die Lösung ist das SourceTag-System: Alles mit EXTERNAL-Tag kommt ohne explizite Nutzerbestätigung nicht ins Langzeitgedächtnis, egal was das Modell vorschlägt.
Phase 5: HeadlessRunner und der Morgenbrief
Ein Agent, der nur auf Anfrage reagiert, ist ein reaktives System. Interessant wird es, wenn er auch proaktiv handelt.
Der HeadlessRunner ermöglicht Tasks ohne aktiven Browser-Nutzer: gleiche Policy-Logik, gleiche Audit-Schicht, aber kein HTTP-Request von außen nötig. Ein interner Scheduler triggert Tasks zeitgesteuert.
Das erste praktische Ergebnis: ein täglicher Morgenbrief per E-Mail. Wetter, Kalendervorschau für die nächsten Tage, konfigurierbare Nachrichten-Feeds aus RSS-Quellen. Was dabei nötig war: strukturierte Daten (Wetter, Kalendertermine) dürfen nicht einfach vom LLM interpretiert werden – dann kommt Halluzination. Die Lösung ist eine direkte Extraktion aus den Tool-Outputs in Python, bevor das LLM den Fließtext formuliert.
Der HeadlessRunner ist jetzt auch die Grundlage für geplante Messenger-Integration. Die Architektur steht – ein Telegram-Webhook wäre eine neue Route plus ein Mapping von externen User-IDs auf interne User-IDs.
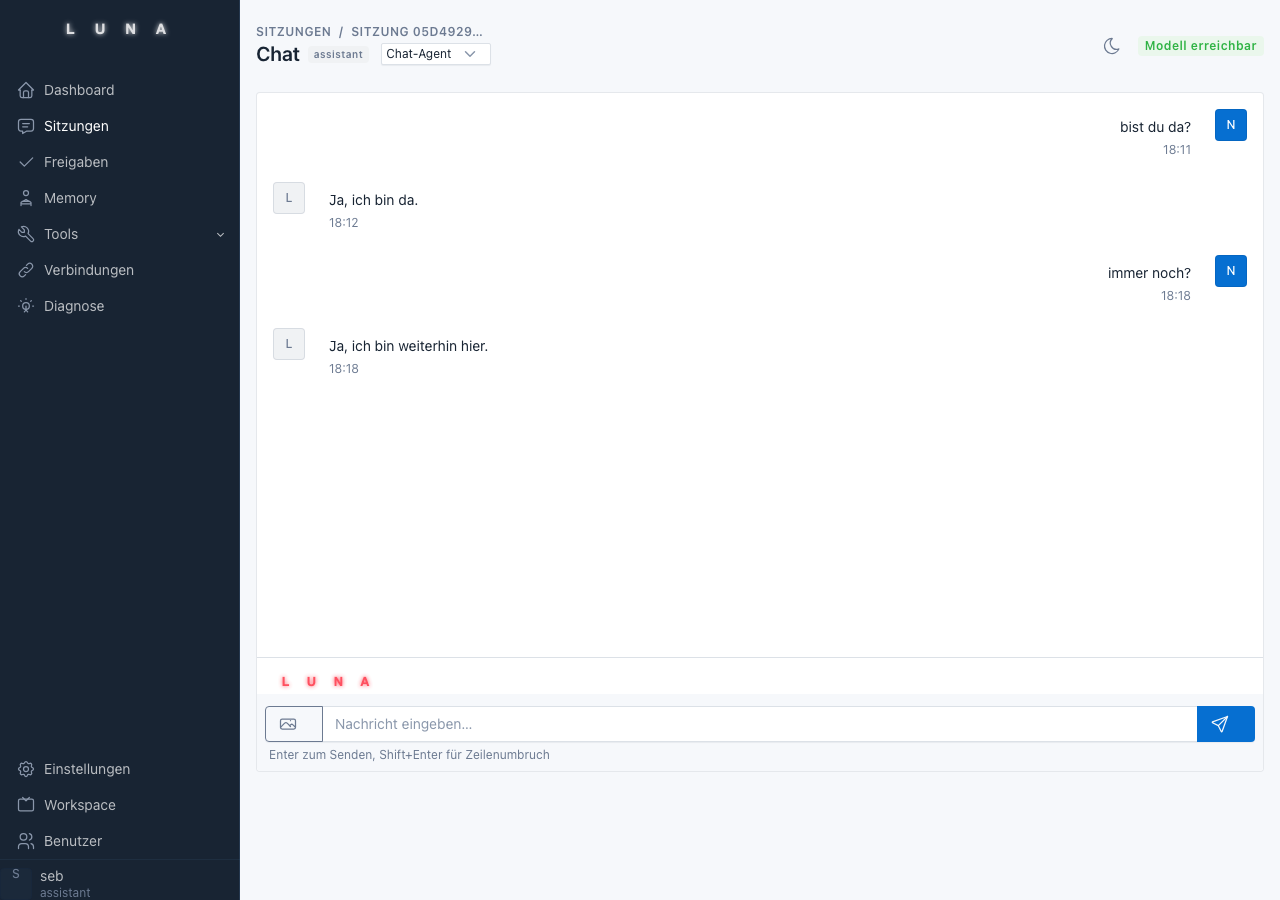
Phase 6: Die Web-UI
Algroveon-Agent hat eine vollständige Browser-Oberfläche, gebaut mit FastAPI, HTMX und dem Tabler-CSS-Framework – vollständig lokal gehostet, kein externer CDN.
Acht UI-Bereiche: Chat-Session, Session-Übersicht, Approval-Center, Memory-Verwaltung, Tool-Referenz, Diagnose, Einstellungen und Admin-Bereich für Nutzerverwaltung. Alle Seiten sind Server-Side-Rendered – kein JavaScript-Framework, kein Build-Schritt.
Was dabei gut funktioniert hat: HTMX für den SSE-Stream. Der Chat-Stream läuft über Server-Sent Events. Eine erste HTTP-Anfrage speichert die Nutzernachricht und gibt sofort eine Antwort zurück: User-Bubble im HTML plus ein Placeholder-Div mit SSE-Verbindungs-Attribut. Ein zweiter GET-Request öffnet den Stream, treibt den Agentic Loop und ersetzt den Placeholder per hx-swap="outerHTML" mit der fertigen Antwort.
Das ergibt reaktives Streaming-Verhalten ohne eine einzige Zeile Frontend-JavaScript für den Stream-Teil.
Phase 7: Algroveon Mac
Die Browser-UI ist vollständig, aber auf dem Desktop wollte ich mehr: ein Menu-Bar-Icon, native Notifications für Approval-Anfragen, Chat ohne Browser-Tab.
Algroveon Mac ist eine reine SwiftUI-App ohne Third-Party-Dependencies. Der Kern-Gedanke: der Mac ist kein zweites KI-System, sondern ein lokaler Tool-Executor. Der LLM läuft auf dem Heimserver. Der Mac übernimmt macOS-native Aktionen: Kalender über EventKit, Adressen über Contacts, Keychain für Token-Speicherung.
Das Kommunikationsprotokoll zwischen Mac-Client und Server nutzt WebSockets mit HMAC-signierten Nachrichten. Der Server dispatcht Tool-Aufrufe an den registrierten Client, der Client führt sie aus und schickt das Ergebnis zurück. Replay-Schutz über einen Ring-Buffer von dispatch-IDs und ein expires_at-Feld verhindert, dass alte Dispatches wieder eingespielt werden.
Was ich dabei gelernt habe
Agentic Systems sind nicht schwierig weil das LLM schlecht wäre. Sie sind schwierig wegen der Orchestrierung: Multi-Turn-Loops, die ausbrechen. Tool-Calls aus Thinking-Blöcken, die fälschlicherweise erkannt werden. Memory-Poisoning über externe Inhalte. Approval-Waits, die im Stream-Kontext blockieren.
Jedes dieser Probleme ist lösbar – aber jedes braucht eigene Logik, und jede Lösung hat eigene Randfälle.
Das Profil-System als zentrale Konfigurationsebene war eine der besten frühen Entscheidungen. Die Policy Engine als deterministischer Sicherheitslayer auch. Beides hätte ich ohne Problembewusstsein vielleicht nicht von Anfang an so gebaut.
Was noch fehlt: RAG für große Dokumente (Grundlage vorhanden), Voice-Interface, Messenger-Integration. Das kommt – der grosse Sprung in Architektur und Sicherheitsmodell ist gemacht.