Algroveon News – Read RSS news locally, without tracking
Why I built my own news feed: RSS without tracking, preferred feeds, with my own AI summaries – local and under complete control.
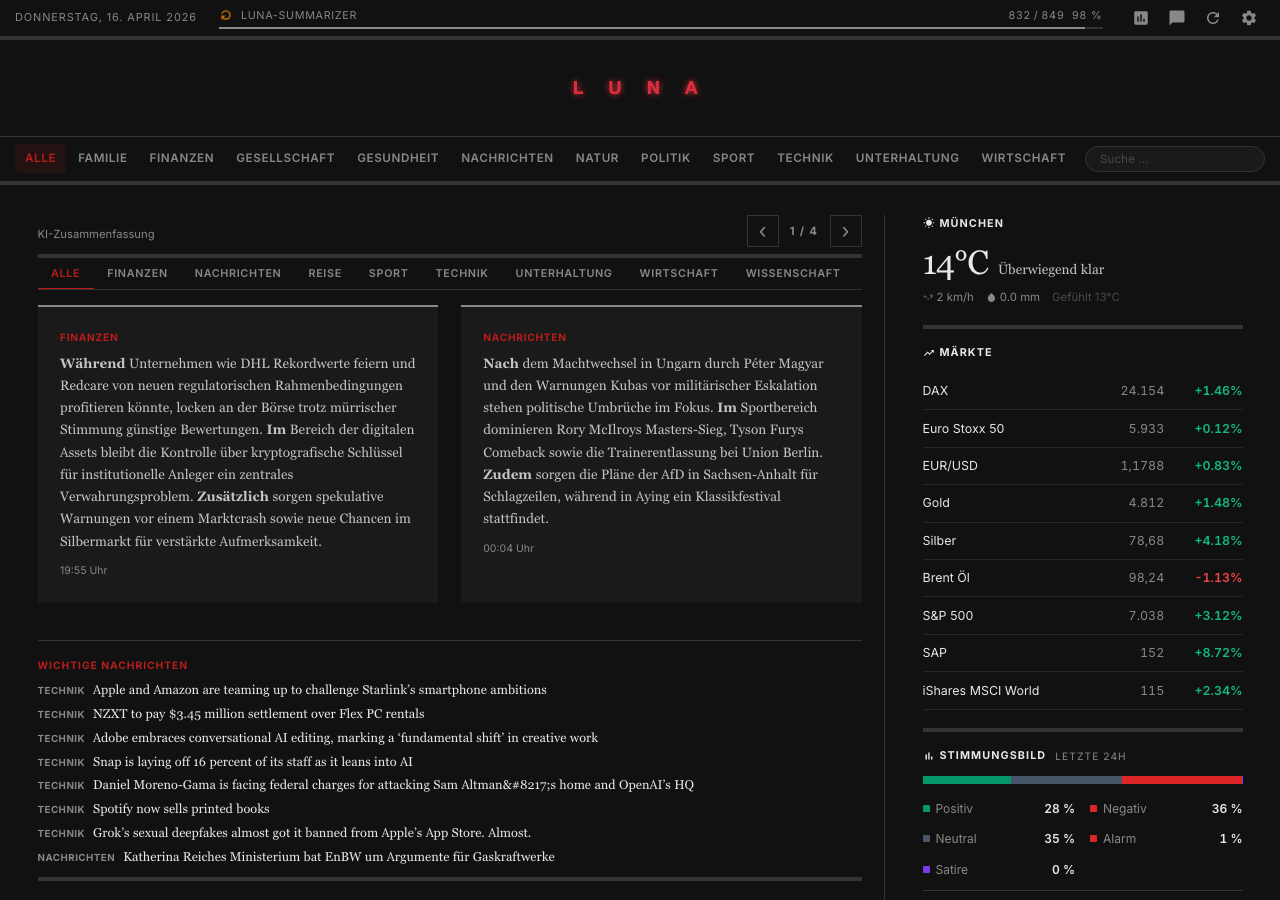
Zusammenfassung
Algroveon-News enables the local reading of RSS feeds without external algorithms or tracking. The tool offers AI-powered summaries and gives users full control over their curated news sources back.
Diese Zusammenfassung wurde mit KI-Unterstützung erstellt.
News Management Instead of News Floods
A daily overview of news events is nothing special. There are more than enough apps and aggregators for that. The problem is: in the end, they decide what lands at the top and what sinks to the bottom.
That is exactly what bothered me. I didn't want a news app that defines relevance through its own algorithm. I wanted my own curated news page based on my personal sources. An interface where it isn't some platform deciding which topics are pushed to the top, but me. I am aware that by doing this, I am initially narrowing my own corridor because I am the one selecting the sources. More diversity is intended to be added in later steps – but not today.
RSS is the right starting point for this – direct sources, full control. But RSS also has a limit: it aggregates, but it doesn't really filter. Anyone who subscribes to twenty feeds will quickly face a hundred articles per day, ten of which cover the same event from ten different sources, without it being immediately clear which one has substance.
This was the actual starting point for Algroveon-News: no foreign weighting, no black-box logic, no external decision-making authority, but my own curated news view – automatically summarized, evaluated for quality, and analyzable over time. Completely local and based precisely on the sources I have deliberately chosen.
Why Not a Ready-Made System
The alternatives were seriously evaluated. Miniflux, FreshRSS, feeds.fun – they all have their strengths. But none of them really fit what was intended to be created here:
| Candidate | Problem |
|---|---|
| Miniflux | Go + PostgreSQL, no LLM, no scoring, too much infrastructure |
| FreshRSS | PHP, wrong stack, no extensibility in the desired direction |
| feeds.fun | No local LLM, no REST API for Algroveon-Agent |
| Commercial Apps | Tracking, algorithms, mandatory cloud |
Ready-made systems always bring their own framework: deployment, updates, dependencies, limitations. That is exactly what I did not want here. What I needed was not a finished system, but a collection of clean building blocks. FastAPI, SQLite, httpx, HTMX – things that I understand, control, and can adapt myself if necessary.
Algroveon-Parser as a Custom Foundation
The most important architectural decision was: to outsource feed parsing first and build a custom foundation for it.
The obvious alternative would have been feedparser – the established Python library. That would have saved time, but it would also have pulled a dependency into the foundation that I can only control to a limited extent. feedparser brings its own logic for HTTP, encodings, and error handling. It is precisely at such points that things become tedious when a feed suddenly behaves unexpectedly and you can no longer cleanly isolate the errors.
The decision was therefore made to create a custom library: algroveon-parser, without external dependencies, in a separate repo with its own tests. Three weeks of work, 16 real feed fixtures as a test suite. The result is a parser that does exactly what is necessary – nothing more and nothing less. Every encoding fallback, every namespace, and every date edge case is traceable, documented, and testable.
In hindsight, this separation was correct. algroveon-parser is now also part of algroveon-agent. A shared, tested parsing layer for multiple projects is ultimately worth significantly more than the time saved in the short term.
Other Dependencies That Were Replaced
feedparser was not the only candidate that was ultimately discarded. The same logic was applied to other external libraries:
| Candidate | Decision | Reason |
|---|---|---|
APScheduler |
Replaced | ~20 lines of asyncio loop are completely sufficient |
yfinance |
Replaced | Unofficial Yahoo wrapper, breaks regularly; ~30 lines of httpx |
| HTMX via CDN | Self-hosted | No external request, no supply-chain risk |
| Inter-Font via CDN | Self-hosted | Same reason – everything is in static/, checked into Git |
The result: during operation, Algroveon-News makes not a single request to external infrastructure except to the subscribed feeds themselves.
The Scoring Approach: Editorial Guidelines Instead of a Black Box
The heart of Algroveon-News is the scorer. Every article is evaluated once by a locally running LLM and receives three properties:
- Sentiment: positive / neutral / negative / alarm / satire
- Quality: 0–1 (0 = clickbait or unsubstantial, 1 = journalistically substantive article)
- Clickbait: true / false
At first glance, this doesn't sound very different from many other LLM systems. However, for me, the difference lies in the foundation: the evaluation logic is not tucked away in some prompt lying silently in the code that changes unnoticed at some point. It is contained in its own prompt file (algroveon_news/resources/redaktions_prompt.txt).
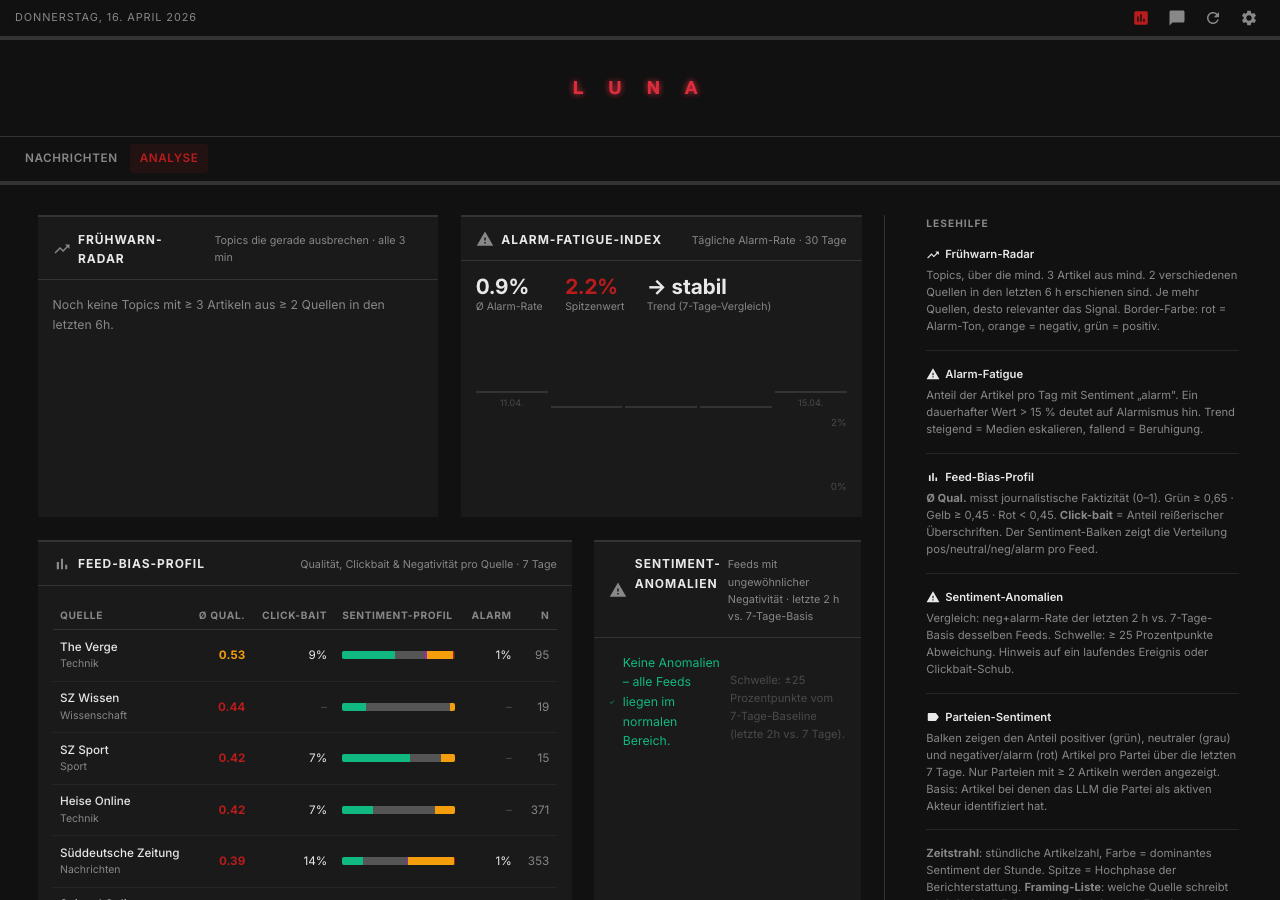
The Analysis Features
Beyond scoring, there are five analysis features that distinguish Algroveon-News from a simple aggregator:
Narrative Tracking
How does a topic evolve over eight weeks? Narrative tracking plots the sentiment distribution for each topic over time: how many articles were positive, neutral, or negative. This makes patterns visible that are easily overlooked during normal reading – for example, a topic that was treated rather neutrally for weeks and then suddenly shifts, or one that suddenly produces an increased number of "alarm" articles.
Silent Alarm
Sometimes the most interesting news is not a headline, but its absence. The Silent Alarm detects topics that appeared regularly – at least three times in 14 days – and have not appeared for 48 hours. A silent, passive monitoring without manual work.
Framing Comparison
The same event can be categorized very differently depending on the source. The framing feature extracts three dimensions per article: core statement, framing type (critical / neutral / alarming / positive / constructive), and implied cause. When expanding a topic, you can see side-by-side how, for example, Spiegel, Tagesschau, and Handelsblatt frame the same facts. Not a fact-check – but a very useful tool to make differences in perspective visible.

Argument Maps
For topics with mixed sentiment – i.e., when the reporting does not clearly lean in one direction – the model synthesizes structured pro/con lists from the available articles. No personal opinion, no artificial balance, but only what the sources actually provide in terms of arguments.
Mini-RAG
Asking questions to your own news database: "What did the ECB decide today?" → FTS5 search across all articles → most relevant hits as context for the LLM → answer with source citations. A context badge indicates whether real hits were found or if the model had to answer without sufficient context. In practice, this is exactly what separates a reliable answer from a hallucination.
The Connection to Algroveon-Agent and Algroveon-AI
Algroveon-News is not an isolated tool. It is a service within my own infrastructure. Algroveon-AI provides the computing power. The LLM (Gemma-4 via Ollama) runs on the home server and processes all summarizer, scorer, and analysis calls. Algroveon-News makes not a single LLM call to an external provider.
Algroveon-Agent is the main consumer of the REST API. When a daily email newsletter (morning briefing) is generated in the morning, Algroveon-Agent queries Algroveon-News – not the feeds themselves live, but the already processed, summarized, and evaluated articles. The actual real-time task of the agent is thus limited to the composition of the briefing and not to feed crawling, parsing, and summarization. This is precisely why Algroveon-News emerged as an independent service in the first place.
Technical Decisions in Retrospect
SQLite instead of PostgreSQL – for a private service with a manageable number of feeds and a few thousand articles per week, SQLite is completely sufficient. A single file, no separate process, easy backup. FTS5 as a built-in extension provides full-text search without additional search infrastructure.
HTMX instead of SPA Framework – the web cockpit is rendered server-side (Jinja2). HTMX provides reactive panel updates without the need for a JavaScript build system. Each analysis panel loads its content via a fragment request with its own refresh interval. This keeps the frontend code very slim.
asyncio-loop instead of APScheduler – the regular tasks are simple enough for a hand-written asyncio loop. Around 20 lines, no additional dependency, no unnecessary underlying structure, no update risk due to foreign breaking changes.
What is Still in Progress
Topic normalization is systematically the most difficult problem. The same topic might appear, for example, as "EZB-Zinsentscheidung", sometimes as "ECB rate decision", and sometimes just as "Zentralbank". The model does not normalize such variants consistently. A canon mapping catches known patterns, but new topics continue to slip through. A truly robust normalization strategy is still an open question here.
Also, the framing quality depends noticeably on the model used and the length of the articles. Short teaser texts – and many feeds provide only a snippet instead of a full content:encoded – often do not yield particularly meaningful framing extracts. This is not a bug in the system, but a real limit of the available data base.